A Comparative Study of WHO and WHEN Prediction Approaches for Early Identification of University Students at Dropout Risk
Publication Details
- Venue
- Conferencia Latinoamericana de Informática
- Year
- 2021
- Publication Date
- August 1, 2021
Materials
Abstract
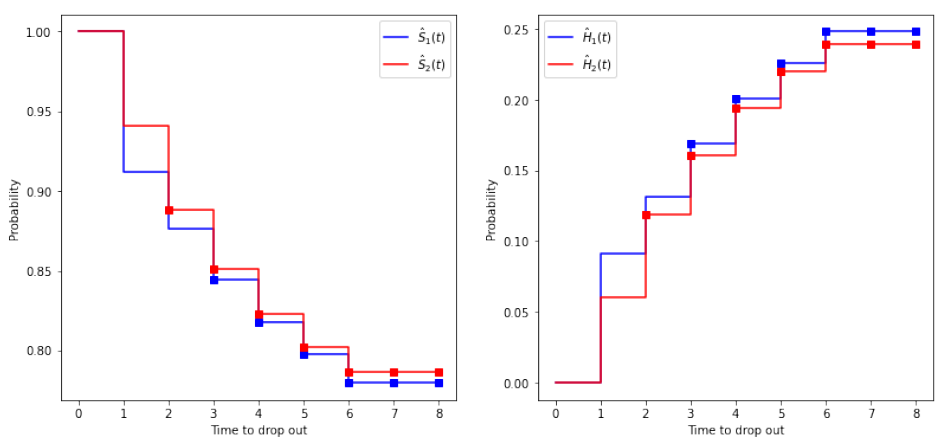
Reducing the students' dropout is one of the biggest challenges faced by educational institutions, especially in underdeveloped countries. Identification of the student with the highest risk of dropping out is generally used to apply corrective actions (WHO). Therefore, it is also important to determine WHEN a student will drop out, which is fundamental to planning preventive actions. In this work, we perform a study to quantitatively compare several approaches to address the early identification of dropout students in universities. We categorize our study into three main methods families, i.e., analytical methods, traditional classification methods, and probabilistic methods. The first is exploited at preprocessing step for selecting significant variables into the dropout identification task. The second uses machine learning models to classify students into dropout prone or non-dropout prone classes. The third family uses survival models to determine when the student would desert. To evaluate the predictive capacity of the classification models, the Kappa coefficient was incorporated into the usual machine learning metrics and shows that Kappa is handy for evaluating performance in unbalanced data. Similarly, in the survival models, the concordance index was applied to evaluate the predictive capacity. Our approach was applied over a real data set of Peruvian university graduate students to identify when and who will drop out.
Cite this publication (BIBTEX)
@article{2021-DropoutAnalysis,
title={A Comparative Study of WHO and WHEN Prediction Approaches for Early Identification of University Students at Dropout Risk},
author={Daniel A. Gutierrez Pachas and Germain García-Zanabria and Alex J. Cuadros-Vargas and Guillermo Cámara-Chávez and Jorge Poco and Erick Gomez Nieto},
journal={Conferencia Latinoamericana de Informática},
year={2021},
url={null},
date={2021-08-01}
}